
Google, si vous lisez ceci, il est trop tard 😉
Ok. Cracks knuckles. Allons droit au but. La documentation interne de l’API Content Warehouse de Google Search a fait l’objet d’une fuite. Les microservices internes de Google semblent refléter ce que Google Cloud Platform offre et la version interne de la documentation pour le Document AI Warehouse déprécié a été accidentellement publiée publiquement sur un dépôt de code pour la bibliothèque client. La documentation de ce code a également été capturée par un service de documentation automatisé externe.
D’après l’historique des modifications, cette erreur de dépôt de code a été corrigée le 7 mai, mais la documentation automatisée est toujours en ligne. Afin de limiter la responsabilité potentielle, je n’y ferai pas référence ici, mais comme tout le code de ce dépôt a été publié sous la licence Apache 2.0, quiconque l’a trouvé s’est vu accorder un large éventail de droits, y compris la possibilité de l’utiliser, de le modifier et de le distribuer de toute façon. 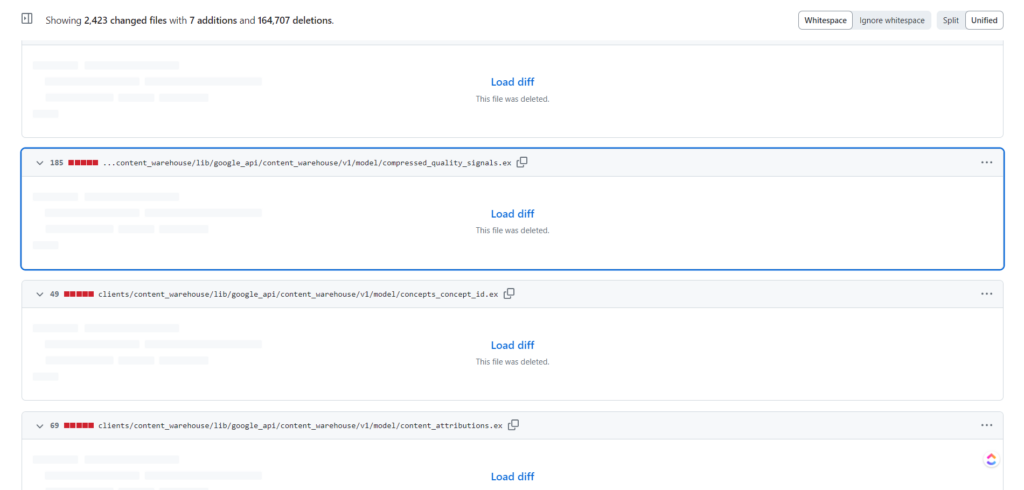
J’ai examiné les documents de référence de l’API et les ai mis en contexte avec d’autres fuites antérieures de Google et le témoignage antitrust du DOJ. Je combine cela avec les recherches approfondies sur les brevets et les livres blancs effectuées pour mon prochain livre, The Science of SEO (La science du référencement). Bien que la documentation que j’ai examinée ne contienne aucun détail sur les fonctions d’évaluation de Google, elle contient une multitude d’informations sur les données stockées pour le contenu, les liens et les interactions avec les utilisateurs. On y trouve également des descriptions plus ou moins détaillées (allant de décevantes à étonnamment révélatrices) des caractéristiques manipulées et stockées.
Vous seriez tenté de les appeler globalement “facteurs de classement”, mais ce serait imprécis. Nombre d’entre eux, voire la plupart, sont des facteurs de classement, mais beaucoup ne le sont pas. Ce que je vais faire ici, c’est mettre en contexte certains des systèmes et fonctionnalités de classement les plus intéressants (du moins, ceux que j’ai pu trouver au cours des premières heures d’examen de cette fuite massive) sur la base de mes recherches approfondies et des choses que Google nous a dites ou menties au fil des ans.
le mot “mentir” est un peu fort, mais c’est le seul mot exact à utiliser ici. Si je ne reproche pas nécessairement aux représentants publics de Google de protéger leurs informations confidentielles, je m’insurge contre leurs efforts visant à discréditer activement les personnes qui, dans le monde du marketing, de la technologie et du journalisme, ont présenté des découvertes reproductibles. Mon conseil aux futurs dirigeants de Google qui s’exprimeront sur ces sujets : Il est parfois préférable de dire simplement “nous ne pouvons pas en parler” Votre crédibilité est importante, et lorsque des fuites comme celle-ci et des témoignages comme ceux du procès du DOJ sont révélés, il devient impossible de faire confiance à vos futures déclarations.
Les mises en garde
Je pense que nous savons tous que des personnes s’efforceront de discréditer les conclusions et l’analyse que j’ai tirées de cette fuite. Certains se demanderont pourquoi c’est important et diront “mais nous le savions déjà” Alors, éliminons les mises en garde avant de passer aux choses sérieuses.
- Temps et contexte limités – En raison du week-end de vacances, je n’ai pu consacrer qu’une douzaine d’heures à l’étude de ce dossier. Je suis incroyablement reconnaissant à certaines parties anonymes qui ont été très utiles en partageant leurs idées avec moi pour m’aider à me mettre à niveau rapidement. Par ailleurs, comme pour la fuite de Yandex que j’ai couverte l’année dernière, je n’ai pas une vision complète de la situation. Alors que nous avions le code source à analyser mais aucune des idées qui le sous-tendaient pour Yandex, dans ce cas-ci, nous avons une partie des idées qui sous-tendent des milliers de fonctionnalités et de modules, mais pas de code source. Vous devrez me pardonner de partager ceci d’une manière moins structurée que je ne le ferai dans quelques semaines, après m’être penché plus longuement sur le sujet.
- Pas de fonctions de notation – Nous ne savons pas comment les caractéristiques sont pondérées dans les diverses fonctions de notation en aval. Nous ne savons pas si toutes les fonctionnalités disponibles sont utilisées. Nous savons que certaines fonctionnalités sont obsolètes. Sauf indication explicite, nous ne savons pas comment les choses sont utilisées. Nous ne savons pas où tout se passe dans le pipeline. Nous disposons d’une série de systèmes de classement nommés qui correspondent vaguement à la manière dont Google les a expliqués, à la manière dont les référenceurs ont observé les classements dans la nature, et à la manière dont les demandes de brevet et la littérature de RI expliquent. En fin de compte, grâce à cette fuite, nous avons maintenant une image plus claire de ce qui est envisagé et qui peut informer ce sur quoi nous nous concentrons par rapport à ce que nous ignorons dans le référencement à l’avenir.
- Probablement le premier d’une série de billets – Ce billet sera mon premier coup de pinceau sur ce que j’ai examiné. Il se peut que je publie d’autres articles au fur et à mesure que je continue à creuser les détails. Je pense que cet article va inciter la communauté SEO à analyser ces documents et que nous allons, collectivement, découvrir et recontextualiser les choses pendant des mois.
- Ces informations semblent être d’actualité – D’après ce que je peux dire, cette fuite représente l’architecture actuelle et active de Google Search Content Storage à partir de mars 2024. (Un responsable des relations publiques de Google vous dira que j’ai tort. En fait, passons la chanson et la danse, vous tous). D’après l’historique des livraisons, le code correspondant a été poussé le 27 mars 2024 et n’a été supprimé que le 7 mai 2024.
- Corrélation n’est pas causalité – Ok, celle-ci ne s’applique pas vraiment ici, mais je voulais juste m’assurer que je couvrais toutes les bases.
Il y a 14 000 caractéristiques de classement et plus encore dans les documents
Il y a 2 596 modules représentés dans la documentation de l’API avec 14 014 attributs (caractéristiques) qui ressemblent à ceci :

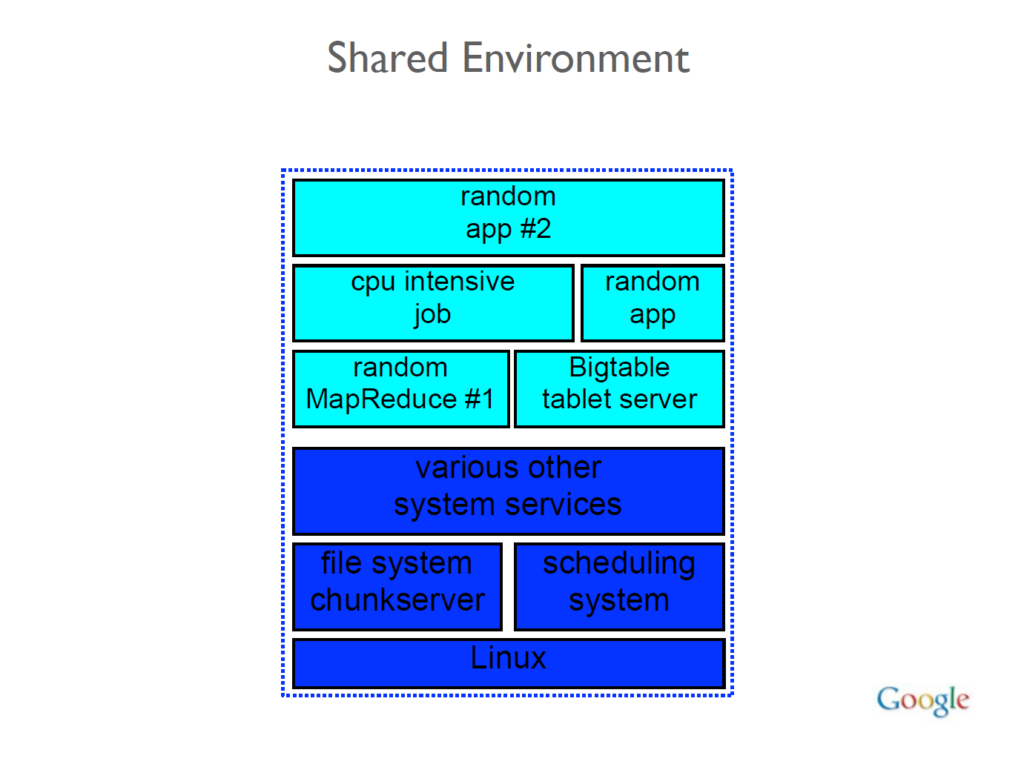
Les modules sont liés à des composants de YouTube, Assistant, Livres, recherche vidéo, liens, documents web, infrastructure de crawl, système de calendrier interne et API Personnes. Techniquement, une grande partie des fonctionnalités n’est donc pas destinée au classement. Tout comme Yandex, les systèmes de Google fonctionnent sur un référentiel monolithique (ou “monorepo”) et les machines fonctionnent dans un environnement partagé. Cela signifie que tout le code est stocké au même endroit et que n’importe quelle machine du réseau peut faire partie de n’importe quel système de Google.
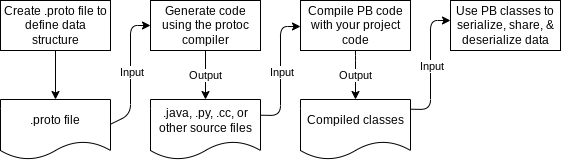
La documentation qui a fait l’objet d’une fuite décrit chaque module de l’API et les décompose en résumés, types, fonctions et attributs. La plupart des éléments que nous examinons sont les définitions des propriétés de divers tampons de protocole (ou protobufs) auxquels les systèmes de classement accèdent pour générer des SERP (Search Engine Result Pages – ce que Google affiche aux internautes après qu’ils ont effectué une requête).
Malheureusement, de nombreux résumés font référence à des liens Go, qui sont des URL sur l’intranet de l’entreprise Google, offrant des détails supplémentaires sur différents aspects du système. Sans les identifiants Google nécessaires pour se connecter et consulter ces pages (ce qui nécessiterait très certainement d’être un Googler de l’équipe de recherche), nous sommes livrés à nous-mêmes pour interpréter.
Les documents de l’API révèlent quelques mensonges notables de Google
Les porte-parole de Google ont tout fait pour nous induire en erreur sur divers aspects du fonctionnement de leurs systèmes, dans le but de contrôler notre comportement en tant que référenceurs. Je n’irai pas jusqu’à parler d'”ingénierie sociale” en raison de l’histoire chargée de ce terme. Je préfère parler d'”éclairage au gaz” Les déclarations publiques de Google ne sont probablement pas des efforts intentionnels pour mentir, mais plutôt pour tromper les spammeurs potentiels (et de nombreux référenceurs légitimes également) afin de nous faire perdre de vue la façon d’influencer les résultats de recherche.
Ci-dessous, je présente des affirmations d’employés de Google ainsi que des faits tirés de la documentation, accompagnés de commentaires limités, afin que vous puissiez juger par vous-même.
Les porte-parole de Google ont déclaré à plusieurs reprises qu’ils n’utilisaient pas “l’autorité de domaine” J’ai toujours pensé qu’il s’agissait d’un mensonge par omission et par dissimulation.
En disant qu’ils n’utilisent pas l’autorité de domaine, ils pourraient dire qu’ils n’utilisent pas spécifiquement la métrique de Moz appelée “Autorité de domaine” (évidemment 🙄). Ils pourraient également dire qu’ils ne mesurent pas l’autorité ou l’importance d’un sujet spécifique (ou domaine) en ce qui concerne un site web. Cette confusion sémantique leur permet de ne jamais répondre directement à la question de savoir s’ils calculent ou utilisent des mesures d’autorité pour l’ensemble du site.
Gary Ilyes, un analyste de l’équipe de recherche de Google qui publie des informations destinées à aider les créateurs de sites web, a répété cette affirmation à de nombreuses reprises.
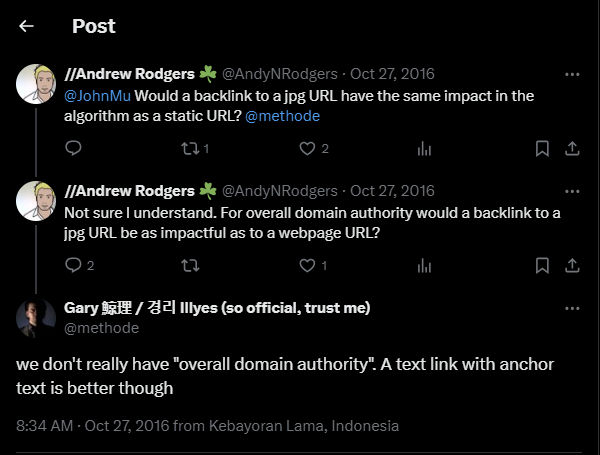
Et Gary n’est pas le seul. John Mueller, un “search advocate qui coordonne les relations de Google avec les moteurs de recherche” a déclaré dans cette vidéo “nous n’avons pas de score d’autorité de site web”
En réalité, dans le cadre des signaux de qualité compressés qui sont stockés pour chaque document, Google dispose d’une fonctionnalité qu’il calcule et qui s’appelle “siteAuthority”
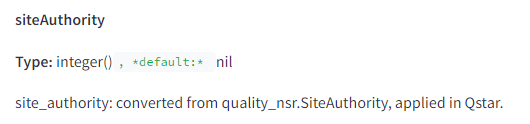
Nous ne savons pas précisément comment cette mesure est calculée ou utilisée dans les fonctions de notation en aval, mais nous savons désormais avec certitude qu’elle existe et qu’elle est utilisée dans le système de classement Q*. Il s’avère que Google a effectivement une autorité de domaine globale. Les Googlers prétendent “nous l’avons, mais nous ne l’utilisons pas”, ou “vous ne comprenez pas ce que cela signifie”, ou… attendez, j’ai dit “commentaires limités”, n’est-ce pas ? Poursuivons.
“Nous n’utilisons pas les clics pour les classements
Mettons celle-ci au placard pour de bon.
Le témoignage de Pandu Nayak dans le procès antitrust du DOJ a récemment révélé l’existence des systèmes de classement Glue et NavBoost. NavBoost est un système qui utilise des mesures basées sur le nombre de clics pour améliorer, rétrograder ou renforcer d’une autre manière un classement dans la recherche sur le Web. M. Nayak a indiqué que Navboost existait depuis 2005 environ et qu’il utilisait traditionnellement des données de clics sur une période de 18 mois. Le système a récemment été mis à jour pour utiliser des données sur 13 mois consécutifs et se concentrer sur les résultats de recherche sur le web, tandis qu’un système appelé Glue est associé à d’autres résultats de recherche universels. Cependant, même avant cette révélation, nous disposions de plusieurs brevets (dont le brevet Time Based Ranking de 2007) qui indiquent spécifiquement comment les journaux de clics peuvent être utilisés pour modifier les résultats.
Nous savons également que les clics, en tant que mesure du succès, constituent une bonne pratique en matière de recherche d’informations. Nous savons que Google s’est orienté vers des algorithmes basés sur l’apprentissage automatique et que l’apprentissage automatique nécessite des variables de réponse pour affiner ses performances. Malgré ces preuves stupéfiantes, la confusion règne toujours dans la communauté des référenceurs en raison de la mauvaise orientation des porte-parole de Google et de la publication complice et embarrassante d’articles dans le monde du marketing de recherche qui répètent sans esprit critique les déclarations publiques de Google.
Gary Ilyes a abordé la question de la mesure des clics à de nombreuses reprises. Dans un cas, il a renforcé ce que Paul Haahr, ingénieur de Google Search, a partagé dans sa conférence SMX West de 2016 sur les expériences en direct, en disant que “utiliser les clics directement dans les classements serait une erreur”

Plus tard encore, il a utilisé sa plateforme pour dénigrer Rand Fishkin (fondateur/PDG de Moz, et praticien SEO de longue date) en disant que “le temps de séjour, le CTR, quelle que soit la nouvelle théorie de Fishkin, ce sont généralement des conneries inventées.”
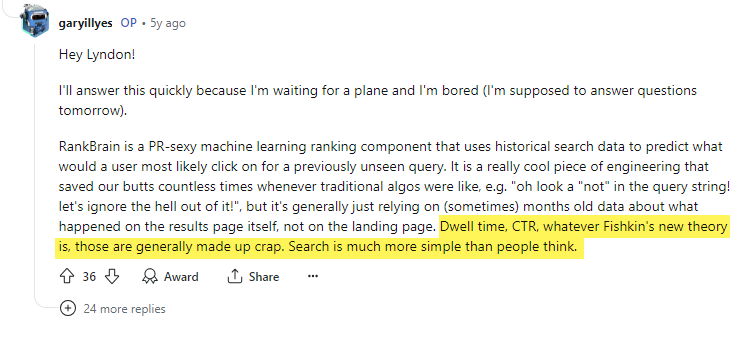
En réalité, Navboost dispose d’un module spécifique entièrement consacré aux signaux de clics.
Le résumé de ce module le définit comme ” les signaux de clics et d’impressions pour le Craps “, l’un des systèmes de classement. Comme nous le voyons ci-dessous, les mauvais clics, les bons clics, les derniers clics les plus longs, les clics non masqués et les derniers clics les plus longs non masqués sont tous considérés comme des métriques. Selon le brevet “Scoring local search results based on location prominence” de Google, “Squashing is a function that prevents one large signal from dominating the others” (l’écrasement est une fonction qui empêche un signal important de dominer les autres) En d’autres termes, les systèmes normalisent les données relatives aux clics afin de s’assurer qu’il n’y a pas de manipulation incontrôlée basée sur le signal de clic. Les Googlers affirment que les systèmes décrits dans les brevets et les livres blancs ne sont pas nécessairement ceux qui sont en production, mais il serait absurde de construire et d’inclure NavBoost s’il ne s’agissait pas d’un élément essentiel des systèmes de recherche d’informations de Google.

Un grand nombre de ces mesures basées sur les clics se retrouvent également dans un autre module relatif aux signaux d’indexation. L’une de ces mesures est la date du “dernier bon clic” sur un document donné. Cela suggère que la dégradation du contenu (ou la perte de trafic au fil du temps) est également fonction du fait qu’une page de classement ne génère pas le nombre de clics escompté pour sa position dans les SERP.
En outre, la documentation représente les utilisateurs comme des électeurs et leurs clics sont stockés comme leurs votes. Le système compte le nombre de mauvais clics et segmente les données par pays et par appareil.
Il enregistre également le résultat qui a fait l’objet du plus long clic au cours de la session. Il ne suffit donc pas d’effectuer une recherche et de cliquer sur le résultat, il faut aussi que les utilisateurs passent beaucoup de temps sur la page. Les clics longs sont une mesure du succès d’une session de recherche au même titre que le temps d’attente, mais il n’existe pas de fonction spécifique appelée “temps d’attente” dans cette documentation. Néanmoins, les clics longs sont effectivement des mesures de la même chose, ce qui contredit les déclarations de Google à ce sujet.
Diverses sources ont indiqué que NavBoost est “déjà l’un des signaux de classement les plus forts de Google”. La documentation qui a fait l’objet d’une fuite mentionne le nom “Navboost” 84 fois et cinq modules comportent Navboost dans leur titre. Il est également prouvé qu’ils envisagent son évaluation au niveau du sous-domaine, du domaine racine et de l’URL, ce qui indique intrinsèquement qu’ils traitent différemment les différents niveaux d’un site. Je n’entrerai pas dans l’argument du sous-domaine par rapport à l’annuaire, mais nous verrons plus tard comment les données du système ont également influencé l’algorithme Panda.
Alors, oui, Google ne mentionne pas le “CTR” ou le “dwell time” par ces mots exacts dans cette documentation, mais l’esprit de ce que Rand a prouvé : les clics sur les résultats de recherche et les mesures d’une session de recherche réussie, sont inclus. La preuve est assez définitive, il ne fait guère de doute que Google utilise les clics et le comportement post-clic dans le cadre de ses algorithmes de classement.
“Il n’y a pas de bac à sable
Les porte-parole de Google ont été catégoriques sur le fait qu’il n’existe pas de bac à sable dans lequel les sites web sont isolés en fonction de leur âge ou de l’absence de signaux de confiance. Dans un tweet aujourd’hui supprimé, John Muller a répondu à une question sur le temps nécessaire pour être éligible au classement en indiquant qu'”il n’y a pas de bac à sable”
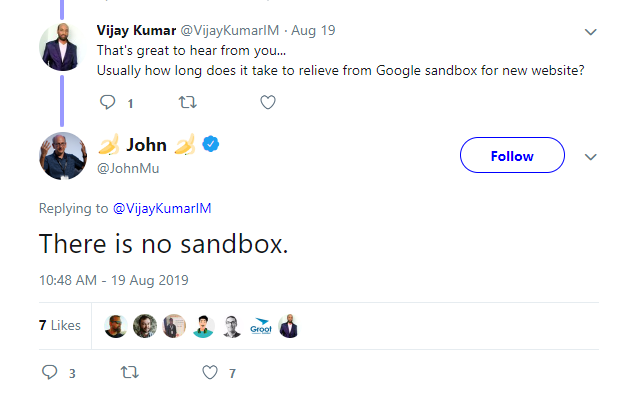
Dans le module PerDocData, la documentation indique un attribut appelé hostAge qui est utilisé spécifiquement “pour mettre le spam frais dans un bac à sable pendant le temps de service”
Il s’avère qu’il existe finalement un bac à sable. Qui le savait ? Oh oui, Rand le savait.
“Nous n’utilisons rien de Chrome pour le classement”
Matt Cutts a déjà déclaré que Google n’utilisait pas les données de Chrome dans le cadre de la recherche organique. Plus récemment, John Muller a renforcé cette idée.

L’un des modules relatifs aux scores de qualité des pages comporte une mesure au niveau du site des vues provenant de Chrome. Un autre module qui semble être lié à la génération de sitelinks comporte également un attribut lié à Chrome.
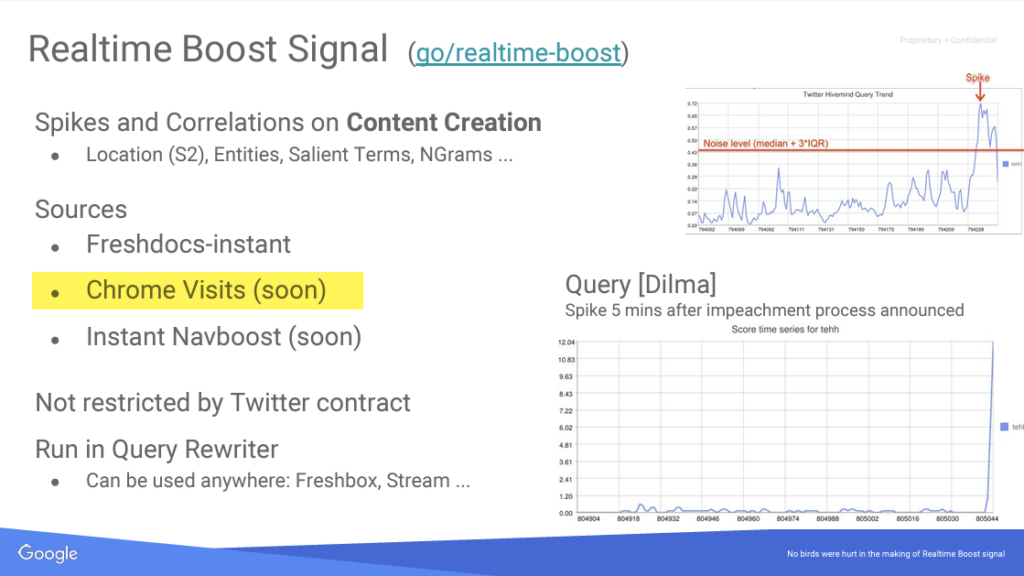
Une présentation interne divulguée en mai 2016 sur le système RealTime Boost indique également que les données de Chrome allaient être intégrées à la recherche. Vous l’aurez compris.
Les porte-parole de Google sont bien intentionnés, mais pouvons-nous leur faire confiance ?
La réponse rapide est non lorsque vous vous approchez trop près de la sauce secrète.
Je ne nourris aucune rancune à l’égard des personnes que j’ai citées ici. Je suis sûr qu’ils font tous de leur mieux pour apporter leur soutien et leur valeur à la communauté dans les limites autorisées. Cependant, ces documents indiquent clairement que nous devons continuer à prendre ce qu’ils disent comme une contribution et que notre communauté doit continuer à expérimenter pour voir ce qui fonctionne.
Suivez les étapes ci-dessus pour ajouter la fonction de similarité cosinus à votre projet.
L’architecture des systèmes de classement de Google
D’un point de vue conceptuel, vous pouvez considérer “l’algorithme de Google” comme une seule et même chose, une équation géante comportant une série de facteurs de classement pondérés. En réalité, il s’agit d’une série de microservices dans lesquels de nombreuses caractéristiques sont prétraitées et mises à disposition au moment de l’exécution pour composer le SERP. D’après les différents systèmes référencés dans la documentation, il pourrait y avoir plus d’une centaine de systèmes de classement différents. En supposant qu’il ne s’agisse pas de tous les systèmes, il se peut que chacun d’entre eux représente un “signal de classement” et que ce soit ainsi que Google arrive aux 200 signaux de classement dont il parle souvent.
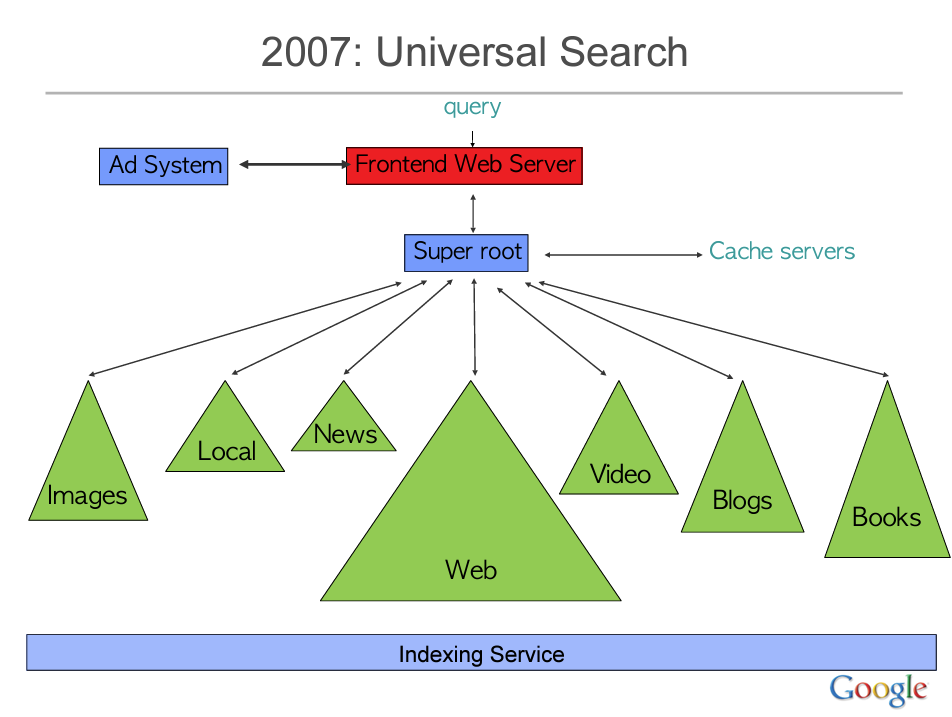
Dans son exposé intitulé “Building Software Systems at Google and Lessons Learned”, Jeff Dean a indiqué que les premières itérations de Google envoyaient chaque requête à 1 000 machines qui la traitaient et y répondaient en moins de 250 millisecondes. Il a également schématisé une version antérieure de l’abstraction de l’architecture du système. Ce diagramme montre que Super Root est le cerveau de Google Search, qui envoie les requêtes et recolle le tout à la fin.
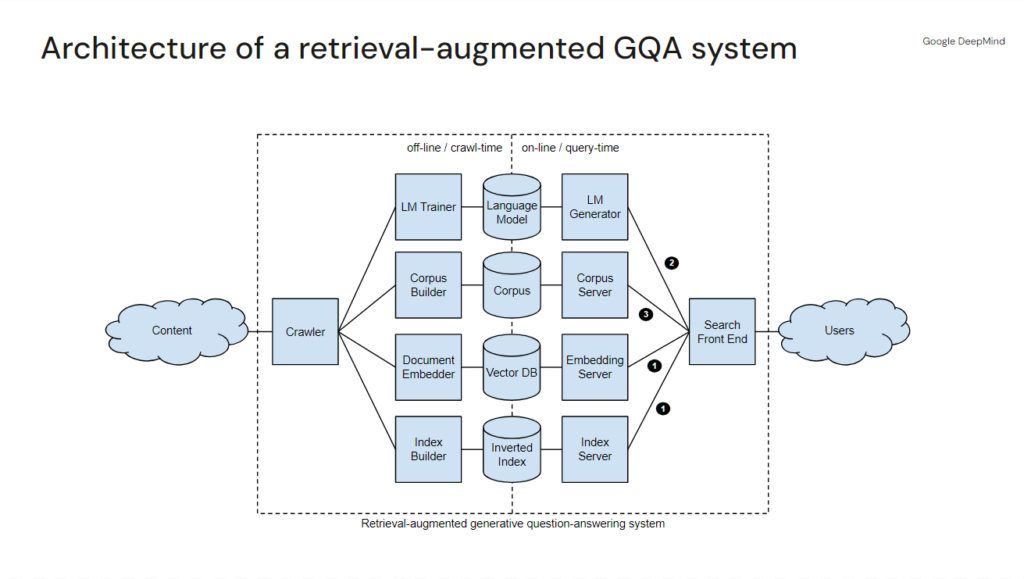
Dans sa récente présentation sur la recherche d’information générative, Marc Najork, ingénieur de recherche distingué, a présenté un modèle abstrait de Google Search avec son système RAG (alias Search Generative Experience/AI Overviews). Ce diagramme illustre une série de magasins de données et de serveurs différents qui traitent les diverses couches d’un résultat.
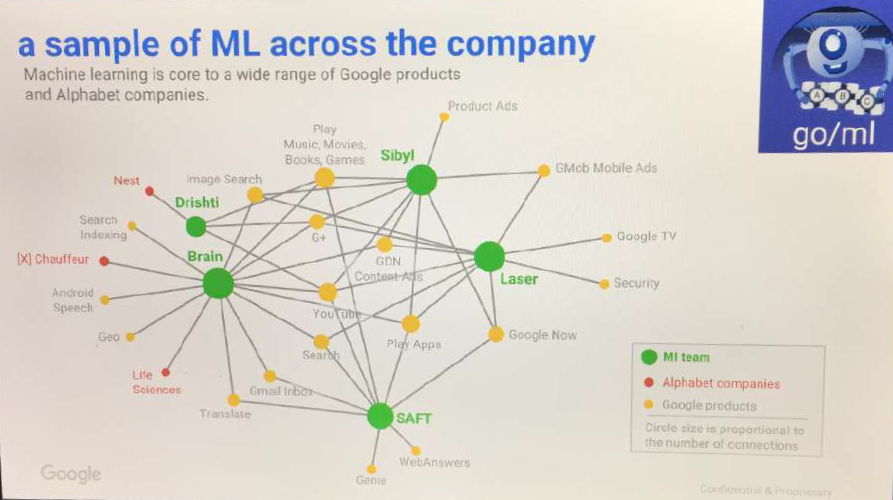
Le dénonciateur de Google, Zach Vorhies, a divulgué cette diapositive qui illustre les relations entre les différents systèmes de Google par leurs noms internes. Plusieurs d’entre eux sont référencés dans la documentation.
En utilisant ces trois modèles de haut niveau, nous pouvons commencer à réfléchir à la manière dont certains de ces composants fonctionnent ensemble. D’après ce que je peux déduire de la documentation, il semble que cette API repose sur Spanner de Google. Spanner est une architecture qui permet une extensibilité infinie du stockage de contenu et du calcul tout en traitant une série d’ordinateurs en réseau mondial comme un seul.
Il est vrai qu’il est quelque peu difficile de reconstituer la relation entre tous les éléments à partir de la seule documentation, mais le curriculum vitae de Paul Haahr donne un aperçu précieux de ce que font certains des systèmes de classement nommés. Je vais mettre en évidence ceux que je connais par leur nom et les segmenter en fonction de leur fonction.
Recherche par crawl
- Trawler – Le système d’exploration du web. Il dispose d’une file d’attente, maintient les taux d’exploration et comprend la fréquence à laquelle les pages changent.
Indexation
- Alexandria – Le système d’indexation principal.
- SegIndexer – Système qui place les documents par niveaux dans l’index.
- TeraGoogle – Système d’indexation secondaire pour les documents qui restent sur le disque à long terme.
Rendu
- HtmlrenderWebkitHeadless – Système de rendu pour les pages JavaScript. Curieusement, il porte le nom de Webkit plutôt que celui de Chromium. Il est fait mention de Chromium dans la documentation, il est donc probable que Google ait utilisé WebKit à l’origine et qu’il ait changé de système après l’arrivée de Headless Chrome.
Traitement
- LinkExtractor – Extrait les liens des pages.
- WebMirror – Système de gestion de la canonicalisation et de la duplication.
Classement
- Mustang – Principal système de notation, de classement et de service
- Ascorer – Algorithme de classement principal qui classe les pages avant tout ajustement du classement.
- NavBoost – Système de reclassement basé sur les journaux de clics du comportement des utilisateurs.
- FreshnessTwiddler – Système de reclassement des documents basé sur leur fraîcheur.
- WebChooserScorer – Définit les noms des caractéristiques utilisées dans l’évaluation des extraits.
Servir
- Google Web Server – GWS est le serveur avec lequel le frontend de Google interagit. Il reçoit les données à afficher à l’utilisateur.
- SuperRoot – C’est le cerveau de Google Search qui envoie des messages aux serveurs de Google et gère le système de post-traitement pour le reclassement et la présentation des résultats.
- SnippetBrain – Système qui génère des extraits de résultats.
- Glue – Système permettant de rassembler des résultats universels en fonction du comportement de l’utilisateur.
- Cookbook – Système de génération de signaux. Certains éléments indiquent que les valeurs sont créées au moment de l’exécution.
Comme je l’ai dit, de nombreux autres systèmes sont décrits dans ces documents, mais leur fonction n’est pas tout à fait claire. Par exemple, SAFT et Drishti du diagramme ci-dessus sont également représentés dans ces documents, mais leurs fonctions ne sont pas claires.
Que sont les Twiddlers ?
Il existe peu d’informations en ligne sur les Twiddlers en général. Je pense donc qu’il est utile de les expliquer ici afin de mieux contextualiser les différents systèmes Boost que nous rencontrons dans les documents.
Les Twiddlers sont des fonctions de reclassement qui s’exécutent après l’algorithme de recherche primaire d’Ascorer. Ils fonctionnent de la même manière que les filtres et les actions dans WordPress, où ce qui est affiché est ajusté juste avant d’être présenté à l’utilisateur. Les Twiddlers peuvent ajuster le score de recherche d’information d’un document ou modifier le classement d’un document. Un grand nombre d’expériences en direct et de systèmes nommés que nous connaissons sont mis en œuvre de cette manière. Comme le montre ce Xoogler, ils sont très importants pour toute une série de systèmes Google :
Les Twiddlers peuvent proposer des contraintes de catégorie, ce qui signifie que la diversité peut être favorisée en limitant spécifiquement le type de résultats. Par exemple, l’auteur peut décider de n’autoriser que 3 articles de blog dans un SERP donné. Cela permet de clarifier les cas où le classement est une cause perdue en raison du format de votre page.
Lorsque Google déclare que quelque chose comme Panda ne fait pas partie de l’algorithme de base, cela signifie probablement qu’il a été lancé en tant que Twiddler comme un calcul de renforcement ou de rétrogradation du classement et qu’il a ensuite été déplacé dans la fonction de notation principale. Pensez-y comme à la différence entre le rendu côté serveur et le rendu côté client
On peut supposer que toutes les fonctions portant le suffixe Boost fonctionnent à l’aide du cadre Twiddler. Voici quelques-unes des fonctions Boost identifiées dans la documentation :
- NavBoost
- QualityBoost
- RealTimeBoost
- WebImageBoost
D’après leurs conventions d’appellation, ils sont tous assez explicites.
Il existe également un document interne sur les Twiddlers que j’ai consulté et qui aborde ce sujet de manière plus détaillée, mais ce billet semble indiquer que l’auteur a consulté le même document que moi.
Des révélations clés qui peuvent avoir un impact sur votre façon de faire du référencement
Venons-en à ce que vous cherchez vraiment. Qu’est-ce que Google fait que nous ne savions pas ou dont nous n’étions pas sûrs et comment cela peut-il avoir un impact sur mes efforts de référencement ?
Petite remarque avant d’aller plus loin. Mon objectif est toujours d’exposer l’industrie du référencement à de nouveaux concepts. Mon but n’est pas de vous donner une prescription sur la façon de l’utiliser pour votre cas d’utilisation spécifique. Si c’est ce que vous voulez, vous devriez engager iPullRank pour votre référencement. Sinon, vous pouvez toujours extrapoler et développer vos propres cas d’utilisation.
Comment fonctionne Panda ?
Lorsque Panda a été mis en place, il y a eu beaucoup de confusion. S’agit-il d’apprentissage automatique ? Utilise-t-il les signaux des utilisateurs ? Pourquoi avons-nous besoin d’une mise à jour ou d’un rafraîchissement pour récupérer ? S’agit-il d’un site entier ? Pourquoi ai-je perdu du trafic pour un certain sous-répertoire ?
Panda a été lancé sous la direction d’Amit Singhal. Ce dernier était résolument opposé à l’apprentissage automatique en raison de son caractère observable limité. En fait, il existe une série de brevets axés sur la qualité des sites pour Panda, mais celui sur lequel je souhaite me concentrer est le non-descriptif “Classement des résultats de recherche” Le brevet clarifie le fait que Panda est beaucoup plus simple que ce que nous pensions. Il s’agissait en grande partie de construire un modificateur de score basé sur des signaux distribués liés au comportement de l’utilisateur et aux liens externes. Ce modificateur peut être appliqué au niveau d’un domaine, d’un sous-domaine ou d’un sous-répertoire.
“Le système génère un facteur de modification pour le groupe de ressources à partir du nombre de liens indépendants et du nombre de requêtes de référence (étape 306). Par exemple, le facteur de modification peut être un rapport entre le nombre de liens indépendants pour le groupe et le nombre de requêtes de référence pour le groupe. En d’autres termes, le facteur de modification (M) peut être exprimé comme suit :
M=IL/RQ,
où IL est le nombre de liens indépendants comptabilisés pour le groupe de ressources et RQ est le nombre de requêtes de référence comptabilisées pour le groupe de ressources”
Les liens indépendants sont essentiellement ce que nous pensons être des liens entre domaines racine, mais les requêtes de référence sont un peu plus complexes. Voici comment elles sont définies dans le brevet :
“Une requête de référence pour un groupe particulier de ressources peut être une requête de recherche précédemment soumise qui a été catégorisée comme se référant à une ressource dans le groupe particulier de ressources. La catégorisation d’une requête de recherche précédemment soumise comme se référant à une ressource dans le groupe particulier de ressources peut inclure : la détermination que la requête de recherche précédemment soumise comprend un ou plusieurs termes qui ont été déterminés comme se référant à la ressource dans le groupe particulier de ressources”
Maintenant que nous avons accès à cette documentation, il est clair que les requêtes de référence sont des requêtes provenant de NavBoost.

Cela suggère que les rafraîchissements Panda étaient simplement des mises à jour de la fenêtre roulante des requêtes, de la même manière que les calculs de Core Web Vitals fonctionnent. Cela pourrait également signifier que les mises à jour du graphe de liens n’ont pas été traitées en temps réel pour Panda.
Sans vouloir faire de procès d’intention, un autre brevet Panda, Site quality score, envisage également un score qui est un rapport entre les requêtes de référence et les sélections ou les clics de l’utilisateur.
En résumé, vous devez obtenir plus de clics réussis en utilisant un ensemble plus large de requêtes et gagner en diversité de liens si vous voulez continuer à vous classer. D’un point de vue conceptuel, c’est logique, car un contenu très solide vous permettra d’atteindre cet objectif. Le fait de se concentrer sur la génération d’un trafic plus qualifié et d’une meilleure expérience utilisateur enverra à Google des signaux indiquant que votre page mérite d’être classée. C’est ce que vous devez faire pour vous remettre de la mise à jour du contenu utile.
Les auteurs sont une caractéristique explicite
Le terme E-E-A-T a fait couler beaucoup d’encre. De nombreux référenceurs n’y croient pas en raison du caractère nébuleux de l’expertise et de l’autorité. J’ai également souligné précédemment à quel point le balisage des auteurs est peu présent sur le web. Avant de découvrir les vector embeddings, je ne pensais pas que l’authorship était un signal suffisamment viable à l’échelle du web.
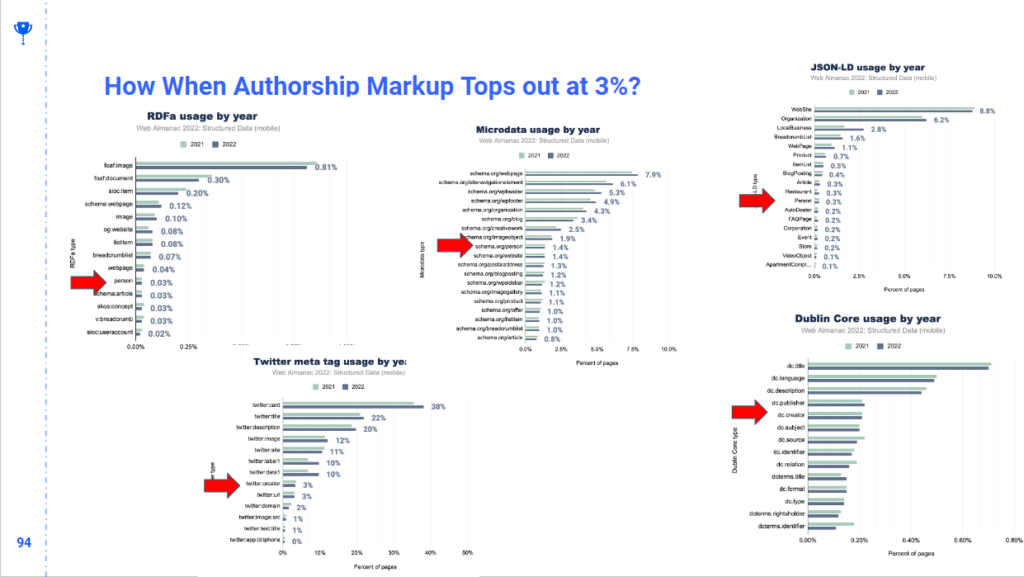
Néanmoins, Google stocke explicitement les auteurs associés à un document sous forme de texte :
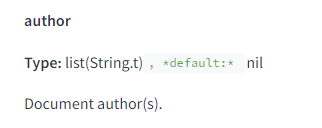
Il cherche également à déterminer si une entité sur la page est également l’auteur de la page.
Si l’on ajoute à cela la cartographie approfondie des entités et des liens présentés dans ces documents, il apparaît clairement que les auteurs font l’objet d’une mesure globale.
Rétrogradations
La documentation présente une série de rétrogradations algorithmiques. Les descriptions sont limitées, mais elles méritent d’être mentionnées. Nous avons déjà parlé de Panda, mais les autres rétrogradations que j’ai rencontrées sont les suivantes :
- Anchor Mismatch – Lorsque le lien ne correspond pas au site cible auquel il renvoie, le lien est rétrogradé dans les calculs. Comme je l’ai déjà dit, Google recherche la pertinence des deux côtés d’un lien.
- Rétrogradation SERP – Signal indiquant une rétrogradation basée sur des facteurs observés dans les SERP, suggérant une insatisfaction potentielle de l’utilisateur à l’égard de la page, probablement mesurée par le nombre de clics.
- Nav Demotion – Il s’agit vraisemblablement d’une rétrogradation appliquée aux pages présentant de mauvaises pratiques de navigation ou des problèmes d’expérience utilisateur.
- Rétrogradation des domaines de correspondance exacte – Fin 2012, Matt Cutts a annoncé que les domaines de correspondance exacte n’auraient plus autant de valeur que par le passé. Il existe une fonctionnalité spécifique pour leur rétrogradation.
- Rétrogradationdes évaluations de produits – Il n’y a pas d’information spécifique à ce sujet, mais c’est listé comme une rétrogradation et probablement lié à la récente mise à jour de 2023 sur les évaluations de produits.
- Rétrogradation en fonction de l’emplacement – Il semblerait que les pages “globales” et “super globales” puissent être rétrogradées. Cela suggère que Google tente d’associer les pages à un lieu et de les classer en conséquence.
- Rétrogradation des pages pornographiques – Cette rétrogradation est assez évidente.
- Autres rétrogradations de liens – Nous en discuterons dans la section suivante.
Toutes ces rétrogradations potentielles peuvent influencer une stratégie, mais elles se résument à la création d’un contenu de qualité, à une expérience utilisateur solide et à la construction d’une marque, si nous voulons être honnêtes.
Les liens semblent toujours aussi importants
Je n’ai vu aucune preuve réfutant les récentes affirmations selon lesquelles les liens sont considérés comme moins importants. Encore une fois, il est probable que cela soit traité dans les fonctions d’évaluation elles-mêmes plutôt que dans la manière dont les informations sont stockées. Cela dit, on a pris grand soin d’extraire et d’élaborer des caractéristiques permettant de comprendre en profondeur le graphe des liens.
Le niveau d’indexation a un impact sur la valeur des liens
Une métrique appelée sourceType montre une relation souple entre le niveau d’indexation d’une page et sa valeur. Pour la petite histoire, l’index de Google est stratifié en niveaux où le contenu le plus important, régulièrement mis à jour et consulté, est stocké dans la mémoire flash. Les contenus moins importants sont stockés sur des disques d’état solide et les contenus mis à jour de manière irrégulière sont stockés sur des disques durs standard.

Cela revient à dire que plus le niveau est élevé, plus le lien a de la valeur. Les pages considérées comme “fraîches” sont également considérées comme de haute qualité. En d’autres termes, vous souhaitez que vos liens proviennent de pages qui sont fraîches ou qui figurent dans le niveau supérieur. Cela explique en partie pourquoi le fait d’obtenir des classements à partir de pages très bien classées et de pages d’actualité permet d’obtenir de meilleurs résultats en termes de classement. Regardez-moi ça, je viens de rendre les relations publiques numériques à nouveau cool !
Signaux de vitesse du spam de liens
Il existe toute une série de mesures concernant l’identification des pics dans le texte d’ancrage des spams. En notant la fonction phraseAnchorSpamDays, Google a effectivement la capacité de mesurer la vitesse des liens de spam.
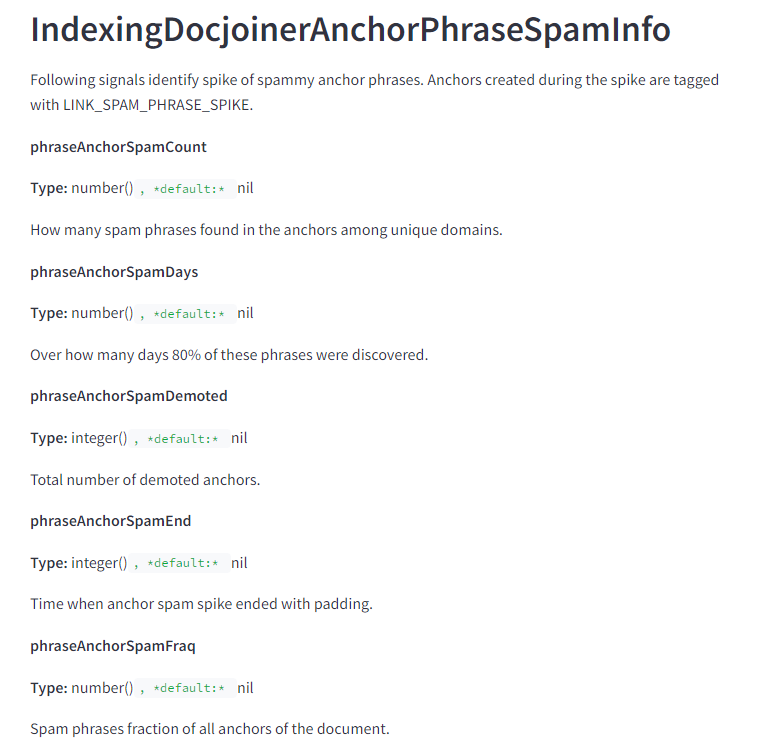
Cela pourrait facilement être utilisé pour identifier quand un site est en train de spammer et pour annuler une attaque de référencement négatif. Pour ceux qui sont sceptiques à ce sujet, Google peut utiliser ces données pour comparer une base de découverte de liens à une tendance actuelle et simplement ne pas compter ces liens dans un sens ou dans l’autre.
Google n’utilise que les 20 dernières modifications pour une URL donnée lors de l’analyse des liens
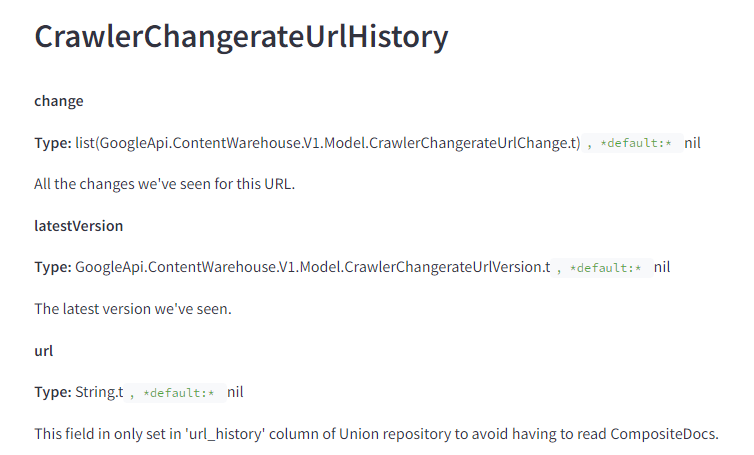
J’ai déjà évoqué la capacité du système de fichiers de Google à stocker des versions de pages au fil du temps, à l’instar de la Wayback Machine. Si j’ai bien compris, Google conserve pour toujours ce qu’il a indexé. C’est l’une des raisons pour lesquelles vous ne pouvez pas simplement rediriger une page vers une cible non pertinente et vous attendre à ce que l’équité des liens soit rétablie.
Les documents renforcent cette idée en indiquant qu’ils conservent tous les changements qu’ils ont jamais vus pour la page.
Lorsqu’ils font remonter les données de surface pour les comparer en récupérant DocInfo, ils ne prennent en compte que les 20 dernières versions de la page.
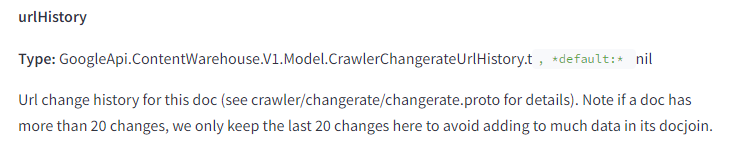
Cela devrait vous donner une idée du nombre de fois où vous devez modifier des pages et les faire indexer pour obtenir une “table rase” dans Google.
Le PageRank de la page d’accueil est pris en compte pour toutes les pages
Chaque document est associé au PageRank de sa page d’accueil (la version la plus proche de la graine). Celui-ci est probablement utilisé comme proxy pour les nouvelles pages jusqu’à ce qu’elles acquièrent leur propre PageRank.

Il est probable que this et siteAuthority soient utilisés comme proxy pour les nouvelles pages jusqu’à ce que leur propre PageRank soit calculé.
Confiance dans la page d’accueil
Google décide de la valeur d’un lien en fonction de la confiance qu’il accorde à la page d’accueil.

Comme toujours, vous devriez vous concentrer sur la qualité et la pertinence de vos liens plutôt que sur le volume.
La taille de la police des termes et des liens est importante
Lorsque j’ai commencé à faire du référencement en 2006, l’une des choses que nous faisions était de mettre le texte en gras et de le souligner ou de grossir certains passages pour qu’ils paraissent plus importants. Au cours des cinq dernières années, j’ai vu des gens dire que cela valait toujours la peine d’être fait. J’étais sceptique, mais je vois maintenant que Google suit la taille de police moyenne pondérée des termes dans les documents.

Il fait de même pour le texte d’ancrage des liens.

Penguin supprime les liens internes
Dans de nombreux modules liés aux ancres, l’idée de “local” signifie le même site. Ce droppedLocalAnchorCount suggère que certains liens internes ne sont pas pris en compte.
Je n’ai pas vu une seule mention de désaveu
Alors que les données de désaveu pourraient être stockées ailleurs, elles ne sont pas spécifiquement dans cette API. Je trouve cela spécifiquement parce que les données des évaluateurs de qualité sont directement accessibles ici. Cela suggère que les données de désaveu sont découplées des systèmes de classement de base.
Mon hypothèse à long terme est que le désaveu a été un effort d’ingénierie de fonctionnalité provenant de la foule pour former les classificateurs de spam de Google. Le fait que les données ne soient pas “en ligne” suggère que cela pourrait être vrai.
Je pourrais continuer à parler de liens et de caractéristiques telles que IndyRank, PageRankNS, etc., mais il suffit de dire que Google a une analyse des liens très précise et qu’une grande partie de ce qu’il fait n’est pas pris en compte par nos indices de liens. C’est le moment idéal pour reconsidérer vos programmes de création de liens sur la base de tout ce que vous venez de lire.
Les documents sont tronqués
Google compte le nombre de jetons et le rapport entre le nombre total de mots dans le corps du texte et le nombre de jetons uniques. Les documents indiquent qu’il existe un nombre maximum de jetons pouvant être pris en compte pour un document spécifique dans le système Mustang, ce qui renforce l’idée que les auteurs doivent continuer à placer leur contenu le plus important en début de page.

Le contenu court est noté en fonction de son originalité
Le score OriginalContentScore suggère que les contenus courts sont notés en fonction de leur originalité. C’est probablement la raison pour laquelle le contenu peu étoffé n’est pas toujours fonction de la longueur.

Inversement, il existe également un score pour le bourrage de mots-clés.
Les titres de page sont toujours mesurés par rapport aux requêtes
La documentation indique qu’il existe un score de correspondance de titre (titlematchScore). La description suggère que la correspondance du titre de la page avec la requête est toujours un élément auquel Google accorde de l’importance.

Placer vos mots-clés cibles en premier est toujours d’actualité.
Il n’y a pas de mesures de comptage de caractères
À sa décharge, Gary Ilyes a déclaré que les référenceurs ont inventé tout le nombre de caractères optimal pour les métadonnées. Il n’y a aucune mesure dans cet ensemble de données qui compte la longueur des titres de page ou des extraits. La seule mesure de comptage de caractères que j’ai trouvée dans la documentation est le snippetPrefixCharCount, qui semble être défini pour déterminer ce qui peut être utilisé dans le cadre de l’extrait.

Cela confirme ce que nous avons constaté à maintes reprises, à savoir que les titres de page longs sont sous-optimaux pour générer des clics, mais qu’ils sont parfaits pour améliorer les classements.
Les dates sont très importantes
Google est très attaché à la fraîcheur des résultats et les documents illustrent ses nombreuses tentatives d’associer des dates aux pages.
- bylineDate – Il s’agit de la date explicitement indiquée sur la page.
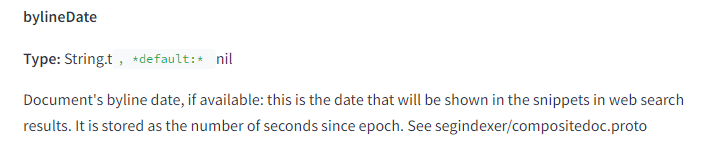
- syntacticDate – Il s’agit d’une date extraite de l’URL ou du titre.

- semanticDate – Il s’agit d’une date dérivée du contenu de la page.

Le mieux est de spécifier une date et d’être cohérent avec celle-ci dans les données structurées, les titres de page et les sitemaps XML. Si vous indiquez dans votre URL des dates qui ne correspondent pas aux dates figurant à d’autres endroits de la page, les performances du contenu seront probablement moindres.
Les informations relatives à l’enregistrement du domaine sont stockées à proximité des pages
Il existe depuis longtemps une théorie du complot selon laquelle le statut de registraire de Google alimente l’algorithme. Nous pouvons maintenant passer à un fait de conspiration. Google stocke les dernières informations d’enregistrement au niveau du document composite.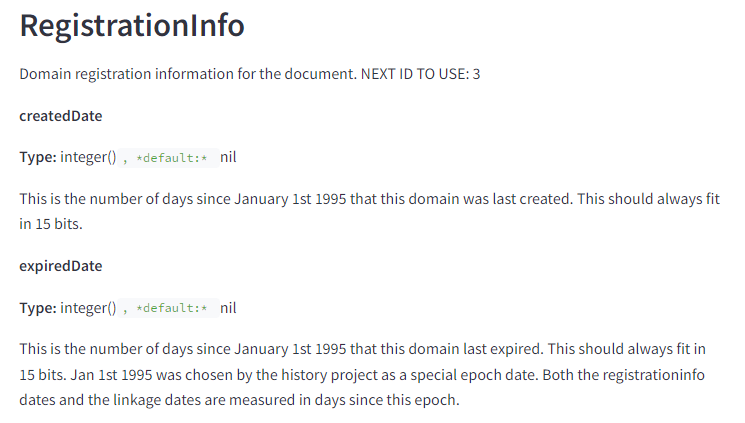
Comme nous l’avons vu précédemment, ces informations sont probablement utilisées pour informer la mise en bac à sable des nouveaux contenus. Elles peuvent également être utilisées pour mettre en bac à sable un domaine déjà enregistré qui a changé de propriétaire. Je soupçonne que le poids de cette question a été récemment augmenté avec l’introduction de la politique de spam sur les domaines expirés.
Les sites axés sur la vidéo sont traités différemment
Si plus de 50 % des pages du site contiennent des vidéos, le site est considéré comme axé sur la vidéo et sera traité différemment.
Votre argent, votre vie fait l’objet d’une évaluation spécifique
La documentation indique que Google dispose de classificateurs qui génèrent des scores pour YMYL Health et pour YMYL News.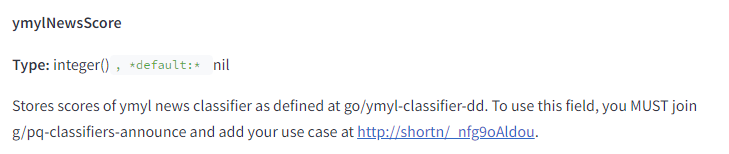
Ils prédisent également les “requêtes marginales” ou celles qui n’ont jamais été vues auparavant afin de déterminer si elles sont YMYL ou non.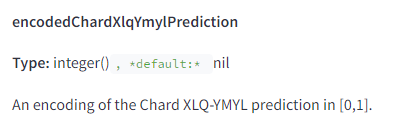
Enfin, YMYL est ancré au niveau des morceaux, ce qui suggère que l’ensemble du système est basé sur des enchâssements.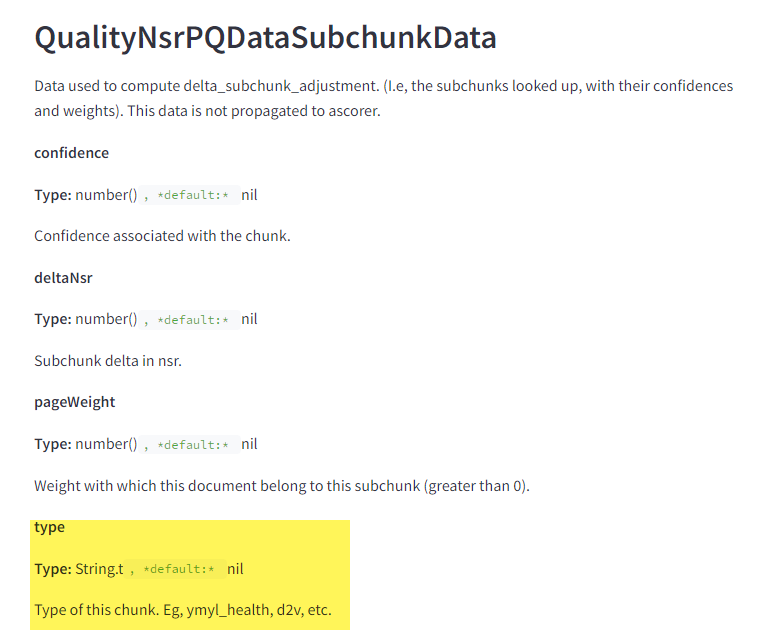
Il existe des documents de référence
Il n’y a pas d’indication sur ce que cela signifie, mais la description mentionne des “documents étiquetés par des humains” par opposition à des “annotations étiquetées automatiquement” Je me demande s’il s’agit d’une fonction des classements de qualité, mais Google affirme que les classements de qualité n’ont pas d’impact sur les classements. Nous ne le saurons donc peut-être jamais. 🤔

Les sites intégrés sont utilisés pour mesurer le degré de pertinence d’une page
Je parlerai plus en détail des embeddings dans un prochain article, mais il est intéressant de noter que Google vectorise spécifiquement les pages et les sites et compare les embeddings des pages aux embeddings des sites pour voir à quel point la page est hors sujet.
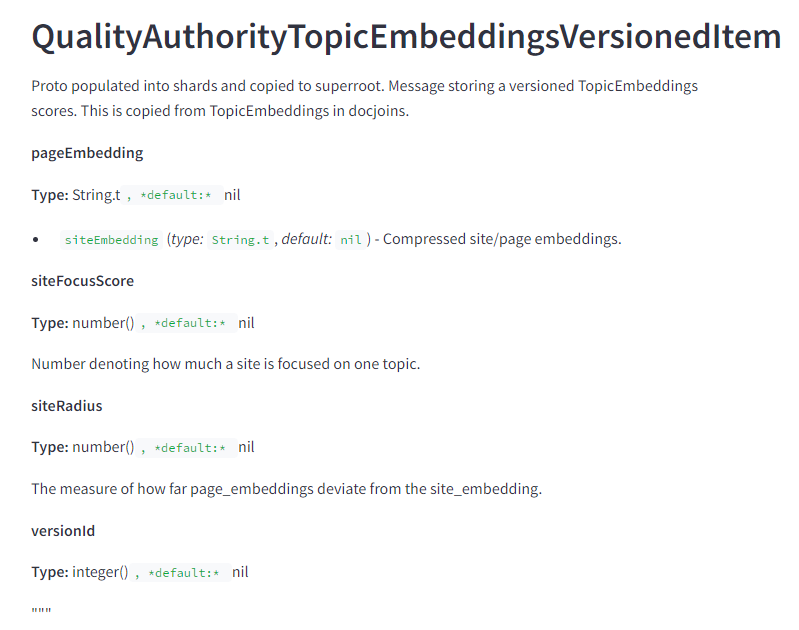
Le score siteFocusScore indique dans quelle mesure le site se concentre sur un seul sujet. Le rayon du site indique dans quelle mesure la page s’écarte du sujet principal sur la base des vecteurs site2vec générés pour le site.
Il se peut que Google brûle volontairement les petits sites
Google dispose d’un indicateur spécifique qui signale qu’un site est un “petit site personnel” Il n’y a pas de définition de ces sites, mais d’après ce que nous savons, il ne serait pas difficile pour Google d’ajouter un Twiddler qui boosterait ces sites ou qui les rétrograderait.

Compte tenu des réactions négatives et des petites entreprises qui ont été détruites par la mise à jour du contenu utile, il est surprenant qu’ils utilisent cette fonctionnalité pour faire quelque chose à ce sujet.
Mes questions ouvertes
Je pourrais continuer, et je le ferai, mais il est temps de faire une pause. Entre-temps, je pense qu’il est inévitable que d’autres personnes s’intéressent à cette fuite et en tirent leurs propres conclusions. Pour l’instant, j’ai quelques questions ouvertes que j’aimerais que nous examinions tous.
La mise à jour du contenu utile est-elle connue sous le nom de Baby Panda ?
Il y a deux références à quelque chose appelé “baby panda” dans les signaux de qualité compressés. Baby Panda est un Twiddler, c’est-à-dire un ajustement qui intervient après le classement initial.
Il est mentionné qu’il fonctionne en plus de Panda, mais il n’y a pas d’autres informations dans les documents.

Je pense que nous sommes généralement d’accord sur le fait que la mise à jour du contenu utile a de nombreux comportements similaires à ceux de Panda. S’il est construit sur un système utilisant des requêtes de référence, des liens et des clics, ce sont les éléments sur lesquels vous devrez vous concentrer après avoir amélioré votre contenu.
NSR signifie-t-il Neural Semantic Retrieval ?
Il existe une multitude de références à des modules et à des attributs dont la convention de dénomination fait référence à NSR. Nombre d’entre eux sont liés à des morceaux de site et à des éléments intégrés. Google a déjà évoqué la “correspondance neuronale” comme l’un des principaux axes d’amélioration. Je suppose que NSR signifie Neural Semantic Retrieval et qu’il s’agit de fonctionnalités liées à la recherche sémantique. Cependant, dans certains cas, elles sont mentionnées à côté d’un “site rank”
J’aimerais bien qu’un Googler rebelle se rende sur go/NSR et m’envoie un “vous avez raison” à partir d’une adresse e-mail anonyme ou quelque chose du genre.
Actions possibles
Comme je l’ai dit, je n’ai pas de prescriptions à vous donner. J’ai cependant quelques conseils stratégiques à vous donner.
- Envoyez des excuses à Rand Fishkin – Depuis mon discours “Everything Google Lied to Us About” (Tout ce que Google nous a menti) à PubCon, je me suis lancé dans une campagne pour blanchir le nom de Rand en ce qui concerne NavBoost. Rand a fait un travail ingrat en essayant d’aider notre industrie à s’élever pendant des années. Pour cela, il a essuyé de nombreuses critiques de la part de Google et des spécialistes du référencement. Parfois, il n’a pas eu raison, mais son cœur était toujours au bon endroit et il s’est efforcé de faire respecter ce que nous faisons et de l’améliorer. En particulier, il ne s’est pas trompé sur les conclusions de ses expériences de clics, sur ses tentatives répétées de démontrer l’existence d’un bac à sable de Google, sur ses études de cas montrant que Google classe différemment les sous-domaines, et sur sa conviction, longtemps contestée, que Google utilise des signaux d’autorité à l’échelle du site. Vous devez également le remercier pour cette analyse, car c’est lui qui a partagé la documentation avec moi. C’est le moment pour beaucoup d’entre vous de lui témoigner de l’amour sur Threads.
- Créez un contenu de qualité et faites-en une bonne promotion – Je plaisante, mais je suis aussi sérieux. Google n’a cessé de donner ce conseil et nous nous en moquons parce qu’il n’est pas applicable. Pour certains référenceurs, c’est tout simplement hors de leur contrôle.
Après avoir passé en revue les caractéristiques qui confèrent à Google ses avantages, il est évident que la création d’un meilleur contenu et sa promotion auprès d’audiences avec lesquelles il est en résonance produiront le meilleur impact sur ces mesures. Les mesures des liens et des caractéristiques du contenu vous permettront certainement d’aller assez loin, mais si vous voulez vraiment gagner dans Google à long terme, vous devrez faire des choses qui continuent à mériter d’être classées.
- Réintroduire les études de corrélation – Nous avons désormais une bien meilleure compréhension de nombreuses caractéristiques que Google utilise pour établir les classements. Grâce à une combinaison de données de parcours et d’extraction de caractéristiques, nous pouvons reproduire plus de choses que nous ne le pouvions auparavant. Je pense qu’il est temps de rétablir les études de corrélation spécifiques aux sites verticaux
- Testez et apprenez – Vous devriez avoir vu suffisamment de graphiques de visibilité et de trafic avec des axes Y pour savoir que vous ne pouvez pas faire confiance à tout ce que vous lisez ou entendez dans le domaine du référencement. Cette fuite est une autre indication que vous devez prendre en compte les données et les expérimenter pour voir ce qui fonctionnera pour votre site web. Il ne suffit pas d’examiner des avis anecdotiques et de supposer que c’est ainsi que Google fonctionne. Si votre organisation n’a pas de plan d’expérimentation pour le référencement, c’est le moment d’en mettre un en place.
Nous savons ce que nous faisons
Une chose importante que nous pouvons tous retenir est que les référenceurs savent ce qu’ils font : Les référenceurs savent ce qu’ils font. Après des années à nous faire dire que nous avons tort, il est bon de voir derrière le rideau et de découvrir que nous avions raison depuis le début. Et, bien que ces documents contiennent des nuances intéressantes sur le fonctionnement de Google, il n’y a rien qui va me faire changer radicalement de cap dans ma stratégie de référencement.
Pour ceux qui s’y intéressent, ces documents serviront avant tout à valider ce que les référenceurs chevronnés préconisent depuis longtemps. Comprenez votre public, identifiez ce qu’il veut, créez la meilleure chose possible qui corresponde à ses attentes, rendez-la techniquement accessible et faites-en la promotion jusqu’à ce qu’elle se classe.
À tous ceux qui travaillent dans le domaine du référencement et qui ne sont pas sûrs de ce qu’ils font, continuez à tester, à apprendre et à développer des entreprises. Google ne pourrait pas faire ce qu’il fait sans nous.
Téléchargez les fonctionnalités de classement
Eh bien, quelqu’un va télécharger et organiser toutes les fonctionnalités dans une feuille de calcul pour vous. Il se pourrait bien que ce soit moi. Il ne nous reste qu’un mois dans le trimestre et je veux augmenter nos MQLs de toute façon. 😆
Téléchargez votre exemplaire de la liste des caractéristiques du classement. Gardez à l’esprit que beaucoup d’entre elles ne sont pas pour le classement, elles sont aussi pour d’autres produits Google.
Nous n’en sommes qu’au début
Ce que j’ai toujours aimé dans le référencement, c’est qu’il s’agit d’un puzzle en constante évolution. Et bien qu’il soit agréable d’aider les marques à gagner des milliards de dollars grâce à nos efforts, il y a quelque chose de très satisfaisant à nourrir ma curiosité avec toutes les recherches liées à l’analyse du fonctionnement de Google. J’ai été très heureux de pouvoir enfin voir ce qui se passe derrière le rideau.
C’est tout ce que j’ai à dire pour l’instant, mais faites-moi savoir ce que vous avez trouvé ! Si vous souhaitez partager quelque chose avec moi, n’hésitez pas à me contacter. Je suis assez facile à trouver !
Prochaines étapes
Voici trois façons dont iPullRank peut vous aider à combiner SEO et contenu pour accroître la visibilité de votre entreprise et générer des revenus :
- Planifiez une session stratégique de 30 minutes : Faites-nous part de vos plus grands défis en matière de référencement et de contenu afin que nous puissions élaborer une présentation personnalisée après avoir examiné votre présence numérique. Il n’y a pas de solutions toutes faites, seulement des conseils sur mesure pour développer votre entreprise. Planifiez votre session dès maintenant.
- Atténuer l’impact potentiel des aperçus de l’IA : Dans quelle mesure votre stratégie de référencement est-elle préparée aux aperçus de l’IA de Google ? Prenez de l’avance sur les menaces potentielles et assurez-vous que votre site reste compétitif grâce à notre rapport complet sur les menaces liées aux aperçus de l’IA. Obtenez votre rapport.
- Améliorez la pertinence de votre contenu avec Orbitwise : Vous n’êtes pas sûr que votre contenu soit mathématiquement pertinent ? Utilisez Orbitwise pour tester et améliorer la pertinence de votre contenu, en vous assurant qu’il se classe pour vos mots-clés ciblés. Testez votre contenu aujourd’hui.
Source : IPullRank (Google Leak)
Article traduit en Français avec ❤️ Par un Consultant SEO et des tools dédiés (c’est plus pratique)


No responses yet